Part 3 - Deployment based on the scoring
Introduction
The previous article transforms our application enabling remote training through a GitHub Action. This remote training is the basis of the current article, which focuses on improving the application’s quality by verifying the trained model’s integrity and correctness.
Here is the code for this article.
Feel free to create an issue to comment on or help us improve here.
Current status
The previous article leads to these files:
- function_app.py: with the application API.
- train.py: running the model training.
- requirements.txt: containing the application dependencies.
- .github/workflows/main_az-fct-python-ml.yml: the GitHub Action workflow running the model training then deploying the API.
Validation steps
Before using a model, it is interesting to carry out some checks. It can be automatic in the form of unit tests or manually by letting a human perform verifications.
This article will:
- Add a unit test for the API.
- Require human validation before deploying the new model.
But before, we will update the training part of the application to collect scoring metrics.
Updating the application
Scoring is not possible with the current dataset. Let’s update the train.py file by creating a larger dataset before adding the scoring step and outputting some model information:
import sysimport pickle
from sklearn.datasets import make_classificationfrom sklearn.model_selection import cross_val_scorefrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import train_test_split
# Define the model.clf = RandomForestClassifier(random_state=0)
# Define the training dataset.X, y = make_classification( n_samples=1000, n_features=3, n_informative=2, n_redundant=0, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train the model on the dataset.clf.fit(X_train, y_train)
# Save the model as a pickle file.with open('model.pkl', 'wb') as f: pickle.dump(clf, f)
# Evaluate the model.scores = cross_val_score(clf, X_test, y_test, cv=5)
# Print some model's information.print('### {scores.mean():.2f} accuracy with a standard deviation of {scores.std():.2f}')Automatic validation
Software testing is standard in software development. Let’s add a test in a file test.py on the API to validate the interface of our application:
import jsonimport pickleimport unittestimport azure.functions as funcfrom sklearn.ensemble import RandomForestClassifierfrom function_app import predict
class TestFunction(unittest.TestCase): X = [[1, 2, 3], [11, 12, 13]] y = [0, 1]
def setUp(self): """ Create a model specifically for the test. """ clf = RandomForestClassifier(random_state=0) clf.fit(self.X, self.y) with open('model.pkl', 'wb') as fd: fd.write(pickle.dumps(clf))
def test_interface(self): # Construct a mock HTTP request. req = func.HttpRequest( method='POST', url='/api/predict', body=json.dumps(self.X).encode() )
# Call the function. func_call = predict.build().get_user_function() resp = func_call(req)
# Check the output. self.assertEqual( json.loads(resp.get_body()), self.y, )
if __name__ == "__main__": unittest.main()This article is not about testing! This application and this test are bad examples of what software testing is. Please think about the idea and the workflow, and not the implementation.
Now, add the following step in the GitHub Action workflow file to perform the test remotely before deploying:
- name: Test the API application run: python test.pyIn case of an error, the GitHub Action stops the workflow and, thus, the deployment.
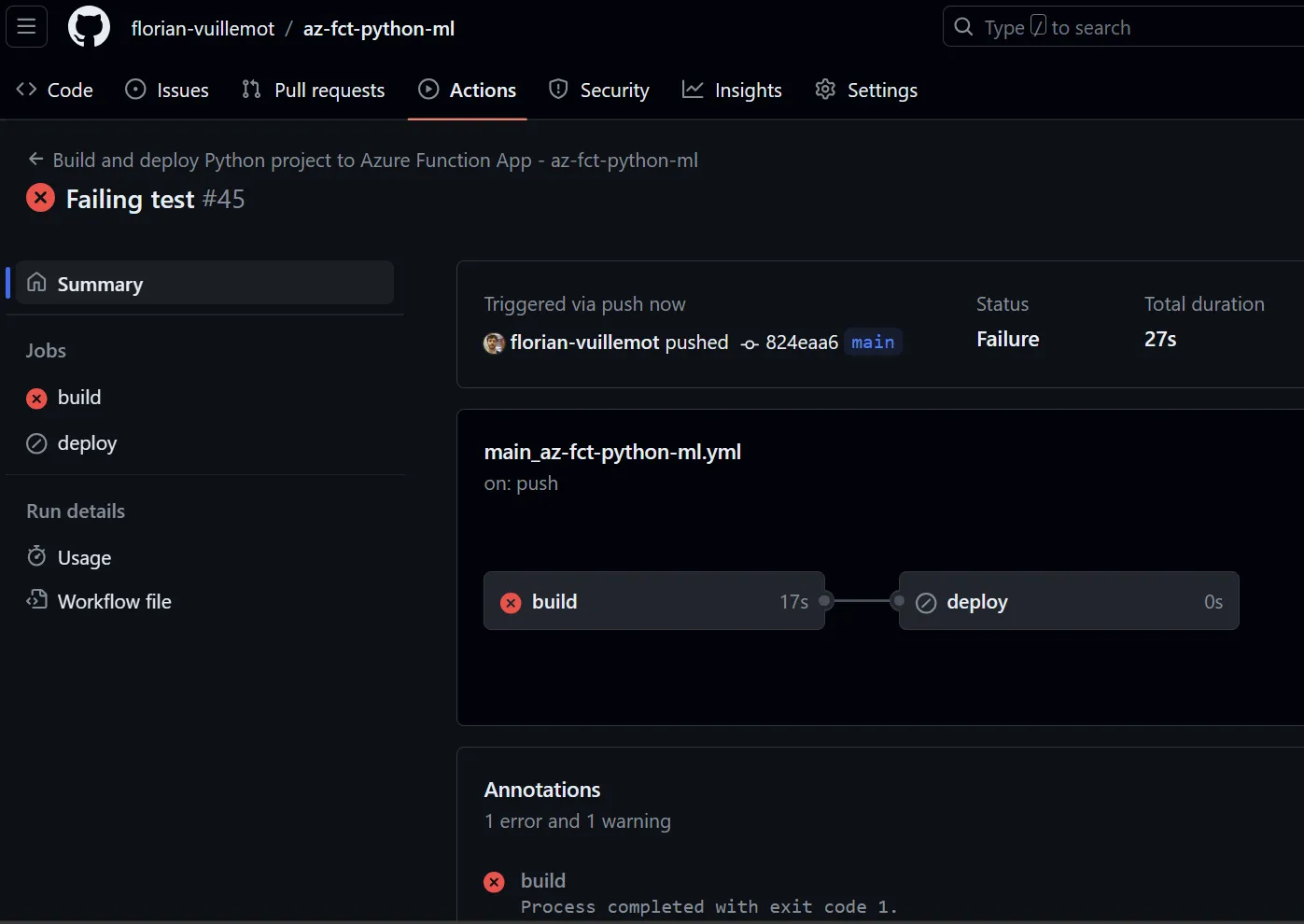
Manual validation
Human validation before updating the production environment is a common use case. GitHub allows this with the environment.
Environments on GitHub not only enable the scoping of secrets and variables, but also the management of protection rules. Protection rules provide a powerful guardrail that protects an environment from common errors. Especially it allows to specify human validators that have to approve changes to let the workflow continue its execution manually.
In fact, our workflow already uses a Production environment created by Azure during the configuration:
deploy: runs-on: ubuntu-latest needs: build environment: name: 'Production' url: ${{ steps.deploy-to-function.outputs.webapp-url }}So, we only need to apply a protection rule to add the human validation:
- Go under the “Settings” bar of the application repository.
- Then click on the “Environments” panel.
- Select “Production”.
- Click “Required reviewers” and add the reviewer: it can be yourself.
- Then click on “Save protection rules”.
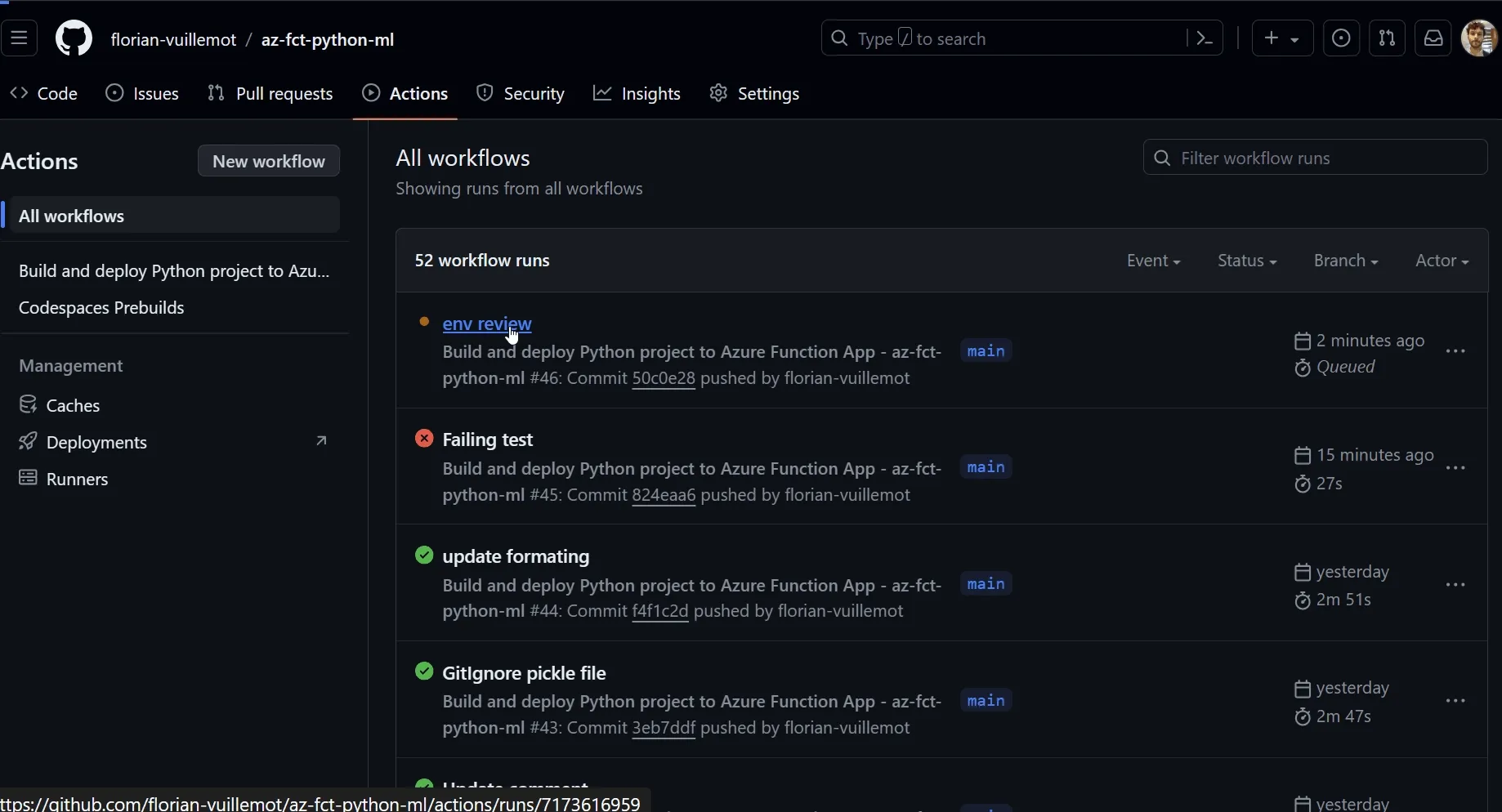
The next time the workflow is executed, it will pause and wait for human validation before performing the deploy step.
For more information about secrets and variables in the context of our application, take a look at the previous article.
Training output
The train.py script prints information about the model:
print('### {scores.mean():.2f} accuracy with a standard deviation of {scores.std():.2f}')This information is essential before validating a deployment, and we want to avoid getting it by searching in the workflow’s logs. GitHub Action makes this possible by using the environment file GITHUB_STEP_SUMMARY. Let’s update the “Train the model” step to display this output:
- name: Train the model run: python train.py >> $GITHUB_STEP_SUMMARYNow, the user can verify the model’s accuracy before deploying it.
Summary and next step
Controlling what is deployed is a step in an application’s journey. After deployment, an application must be monitored, and depending on the metrics, a rollback can take place. As explained in the following article, rollbacks can be automated, just as deployments.
Any comments, feedback, or problems? Please create an issue here.