Part 5 - Increasing the model size
Introduction
The previous article allows deployment rollback improving reliability in case of deployment failure. Unfortunately, each deployment impacts the application’s reliability and contains a risk, especially in our case because we are training a model that can rely on a random state. Besides, its size is limited because the model is in the artifact and mixed with the application code.
Here is the code for this article.
Feel free to create an issue to comment on or help us improve here.
Current status
The previous article leads to these files:
- function_app.py: with the application API.
- train.py: running the model training.
- test.py: testing the API.
- requirements.txt: containing the application dependencies.
- .github/workflows/main_az-fct-python-ml.yml: the GitHub Action workflow doing the model training, asking for deployment validation then deploying the API.
We also created the Microsoft Entra application az-fct-python-ml.
Azure File Share
Azure File Share is a managed Azure service that allows remote file storage. It provides a simple and secure way to store structured and unstructured data, as in our case, a machine learning model. Azure File Share and Azure Function are well integrated, and we will use both together to serve a model that can become multi-Gb without problem.
Another advantage of using Azure File Share with Azure Function is the possibility of decoupling the model and API deployments. Indeed, because it’s on the Azure File Share, the model doesn’t need to be in the artifact anymore, and workflows can be rewritten as:
Creates the Azure File Share
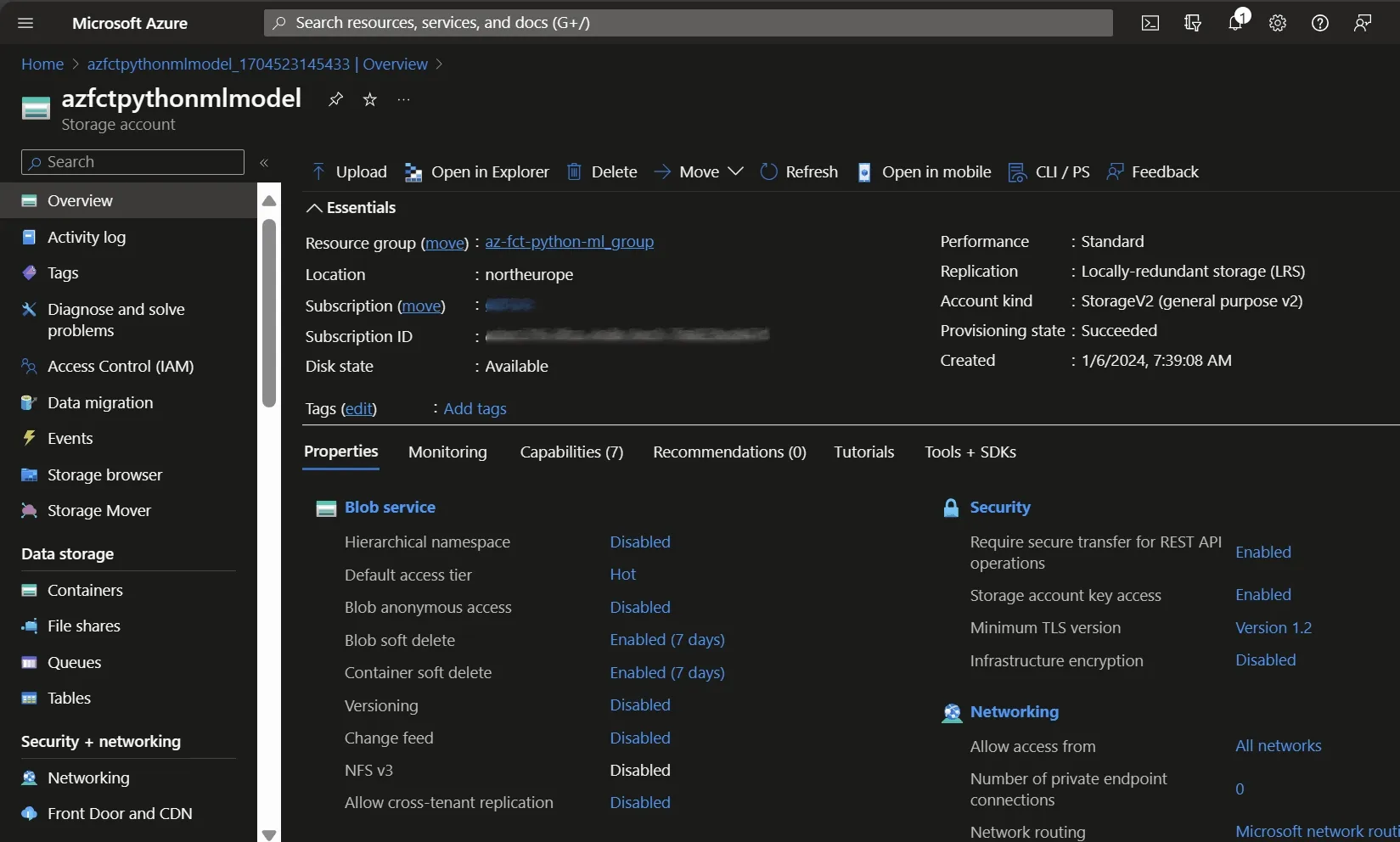
Azure File Share is not a service directly instantiable from Azure. Azure Storage Account holds it. To create a File Share, let’s first create an Azure Storage Account:
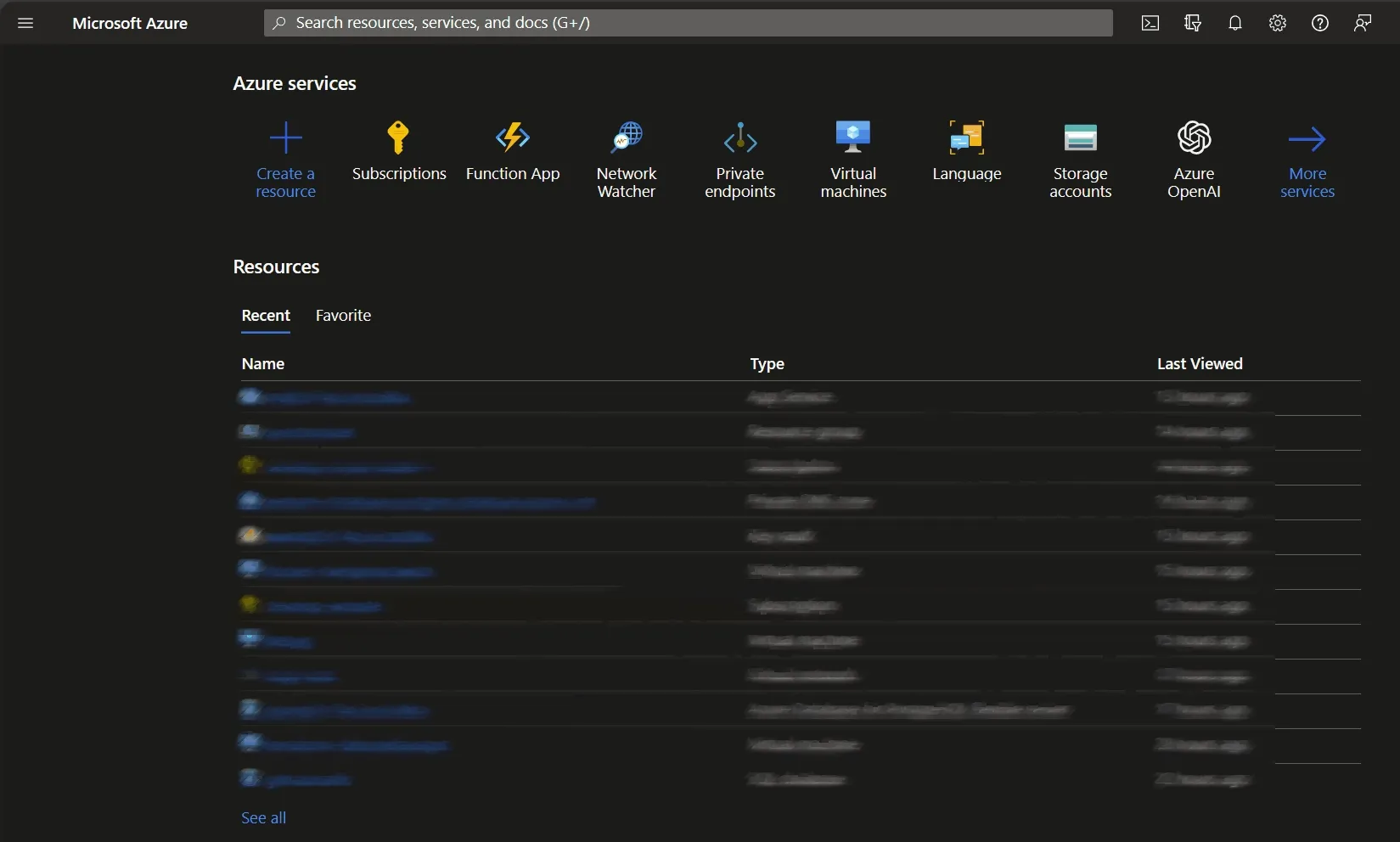
Now let’s create the File Share models:
Exposing the model
Because the model will no longer be in the artifact but on an Azure File Share, we must upload the model on it after its training. This implies the creation of a new GitHub Action workflow with the upload permission.
Update permissions
Go on the Azure File Share, then the IAM panel, and add the role “Storage Account Contributor” to the Microsoft Entra application az-fct-python-ml used by the GitHub Action workflow.
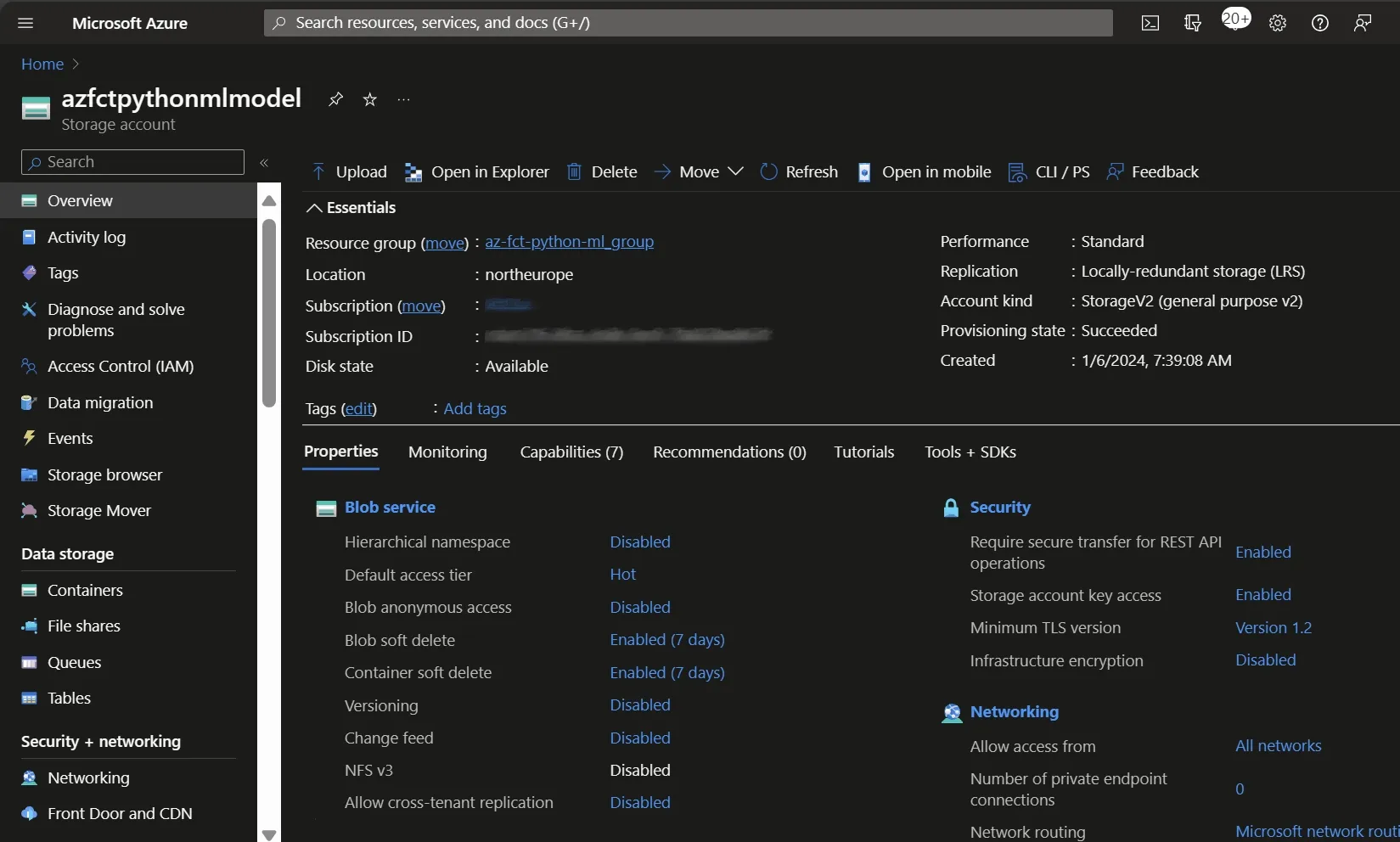
This permission is broad and can be improved.
Updates the GitHub Action workflow
Using Azure File Share we can now create two workflows instead of our current:
- Updating the API: Create a new artifact containing the application code only and deploy it on the Azure Function.
- Updating the model: Train the model, then upload it to the Azure File Share.
But what about rollbacking the model? Azure proposes nothing in our case. But we can implement the same process then with Azure Function. We can create two files on the File Share, one with the current running model and the other with the previous model, then erase the previous model with the current and the current with the new model during the model’s deployment. In case of a problem, we roll out the previous working model in the blue-green mindset.
Blue-green deployment with Azure Function is our context explained here.
Updates the API workflow
We no longer need to train the model in the current workflow, so let’s remove this part from our build job:
- name: Train the model run: python train.py >> $GITHUB_STEP_SUMMARYAnd that’s all! Let’s now create the job replacing this step.
Trains the model workflow
Let’s create a new job doing the training and the upload. This job also keeps the previous model available for rollback. The first part is the same as the build steps and can be refactored later.
train: runs-on: ubuntu-latest environment: name: 'Production' steps: - name: Checkout repository uses: actions/checkout@v4
- name: Setup Python version uses: actions/setup-python@v1 with: python-version: ${{ env.PYTHON_VERSION }}
- name: Create and start a virtual environment run: | python -m venv venv source venv/bin/activate
- name: Install the dependencies run: pip install -r requirements.txt
- name: Train the model run: python train.py >> $GITHUB_STEP_SUMMARY
- name: 'Az CLI login' uses: azure/login@v1 with: client-id: ${{ secrets.AZURE_CLIENT_ID }} tenant-id: ${{ secrets.AZURE_TENANT_ID }} subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }} enable-AzPSSession: true
- name: Backup the current model if it exists continue-on-error: true run: | # Download the current model az storage file download --path ${{ env.CURRENT_MODEL_NAME }} --account-name ${{ env.STORAGE_ACCOUNT_NAME }} --share-name ${{ env.FILE_SHARE_NAME }} --dest /tmp/previous-model # Upload the current model named as the previous model to the file share az storage file upload --path ${{ env.PREVIOUS_MODEL_NAME }} --account-name ${{ env.STORAGE_ACCOUNT_NAME }} --share-name ${{ env.FILE_SHARE_NAME }} --source /tmp/previous-model
- name: Replace the current model with the new one run: | # Upload the new model to the file share az storage file upload --path ${{ env.CURRENT_MODEL_NAME }} --account-name ${{ env.STORAGE_ACCOUNT_NAME }} --share-name ${{ env.FILE_SHARE_NAME }} --source ${{ env.CURRENT_MODEL_NAME }}Rollback the model
Now, you can enable rollback by adding the following job. The review of the Production environment is the safeguard.
swap-current-and-previous-model: runs-on: ubuntu-latest needs: train environment: name: 'Production' steps: - name: 'Az CLI login' uses: azure/login@v1 with: client-id: ${{ secrets.AZURE_CLIENT_ID }} tenant-id: ${{ secrets.AZURE_TENANT_ID }} subscription-id: ${{ secrets.AZURE_SUBSCRIPTION_ID }} enable-AzPSSession: true
- name: Rollback the model run: | # Download the previous model az storage file download --path ${{ env.PREVIOUS_MODEL_NAME }} --account-name ${{ env.STORAGE_ACCOUNT_NAME }} --share-name ${{ env.FILE_SHARE_NAME }} --dest /tmp/previous-model # Download the current model az storage file download --path ${{ env.CURRENT_MODEL_NAME }} --account-name ${{ env.STORAGE_ACCOUNT_NAME }} --share-name ${{ env.FILE_SHARE_NAME }} --dest /tmp/current-model
# Upload the previous model as the current az storage file upload --path ${{ env.CURRENT_MODEL_NAME }} --account-name ${{ env.STORAGE_ACCOUNT_NAME }} --share-name ${{ env.FILE_SHARE_NAME }} --source /tmp/previous-model # Upload the current model as the previous az storage file upload --path ${{ env.PREVIOUS_MODEL_NAME }} --account-name ${{ env.STORAGE_ACCOUNT_NAME }} --share-name ${{ env.FILE_SHARE_NAME }} --source /tmp/current-modelWe can now train, deploy, and roll back our model independently.
Consumming the model
The simpler way to use the generated model is to mount the Azure File Share as a folder in our Azure Function. In that case, the model will be accessible directly as a file by the application.
Mount File Share
You must use a terminal or a Cloud Shell to run the command line mounting the Azure File Share under the Azure Function. This command needs to be run once. In our case, the File Share will be mounted on the default Production slot only.
az webapp config storage-account add --account-name azfctpythonmlmodel --access-key <access-key> --custom-id models --share-name "models" --storage-type AzureFiles --resource-group az-fct-python-ml_group --name az-fct-python-ml --mount-path "/models"More information on this command here.
Then restart the Function. It is impossible to retrieve Azure Function mounted files from the Azure Portal.
Update the application
Models are now available under the folder /models. Consequently, the only element to update in the application is the model path. We will use environment variables to be generic and allow testing instead of hard coding the path.
Update the function_app.py file and propagate those changes to the test.py file:
import os
MODEL_PATH = os.environ.get('MODEL_PATH')
...
with open(MODEL_PATH, 'rb') as f:Then update the GitHub Action workflow build job to create the model in a temporary folder and not pollute the artifact.
- name: Test the API application run: python test.py env: MODEL_PATH: /tmp/model.pklFinally, add the new environment variable on the Azure Function.
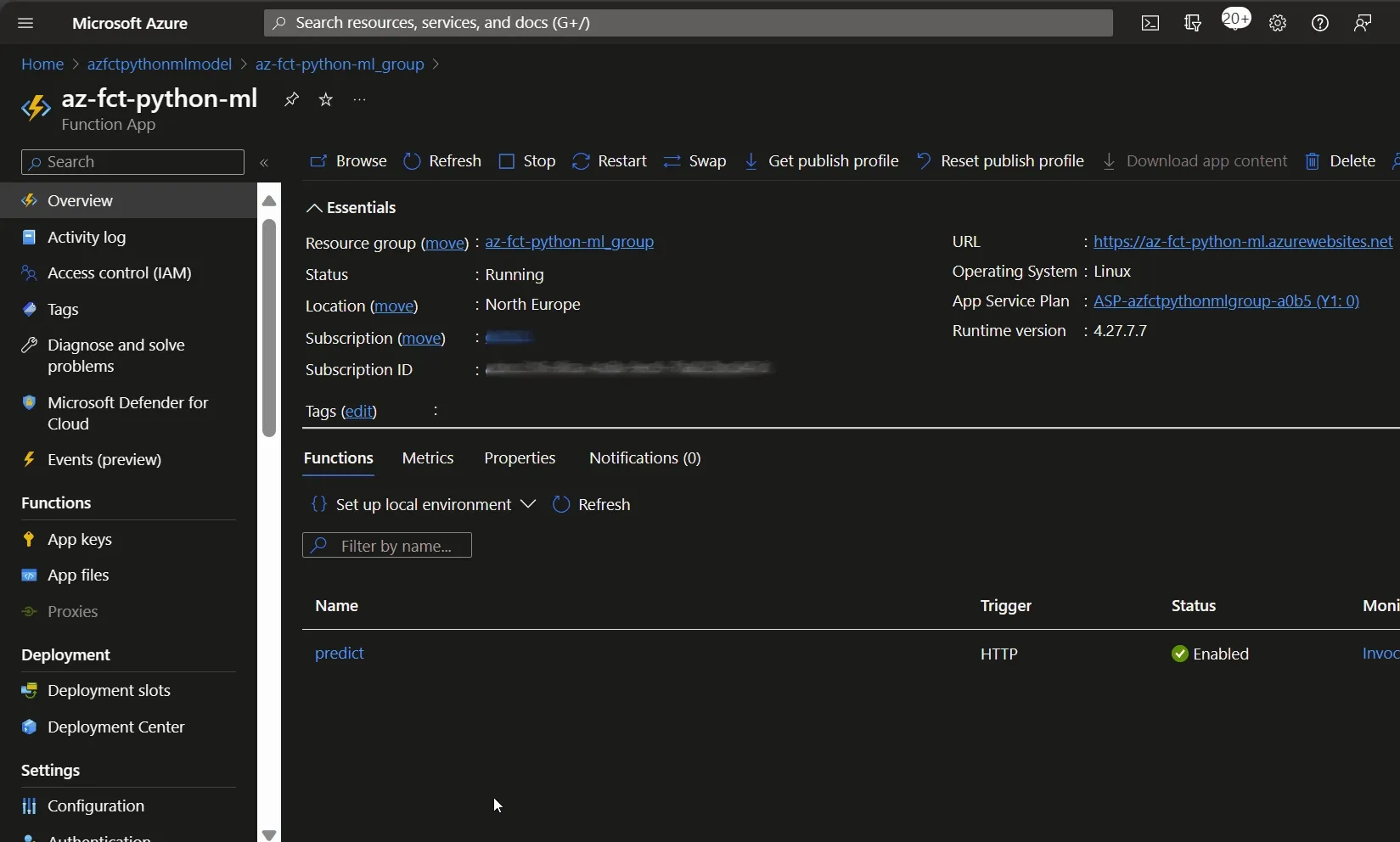
And that is it! The API will now serve the model from the File Share and so serve each new model when deployed by the train workflow.
The serverless nature of Azure Function leads to loading the model on each call. This can be time-consuming due to the network access and model size. Consider using another computing service such as Azure Web App.
Summary and next step
Decoupling API and model deployment improves the deployment process and system agility but increased the time of the CI/CD. Workflows are code, and like all code, refactoring is important, as we’ll see in the next article.
Any comments, feedback or problems? Please create an issue here.